Backpropagation
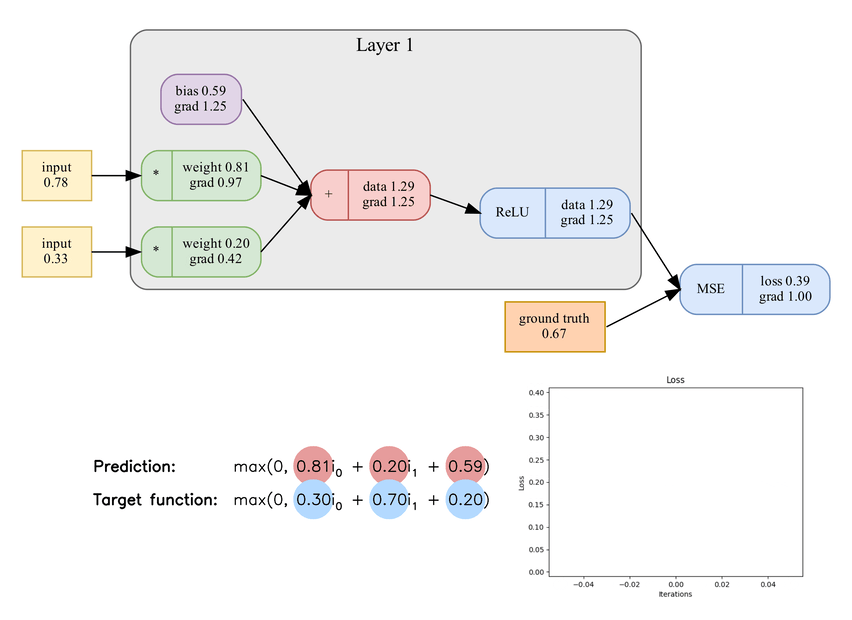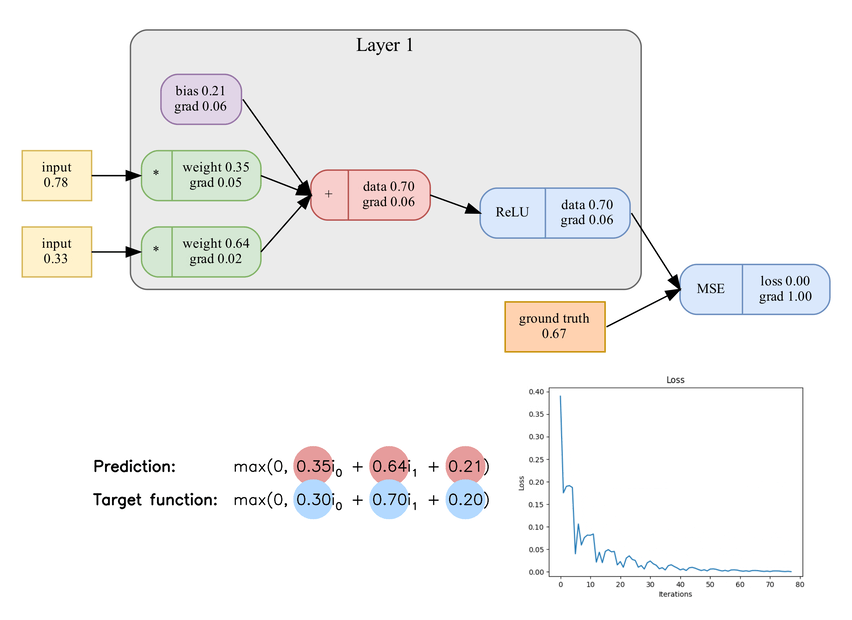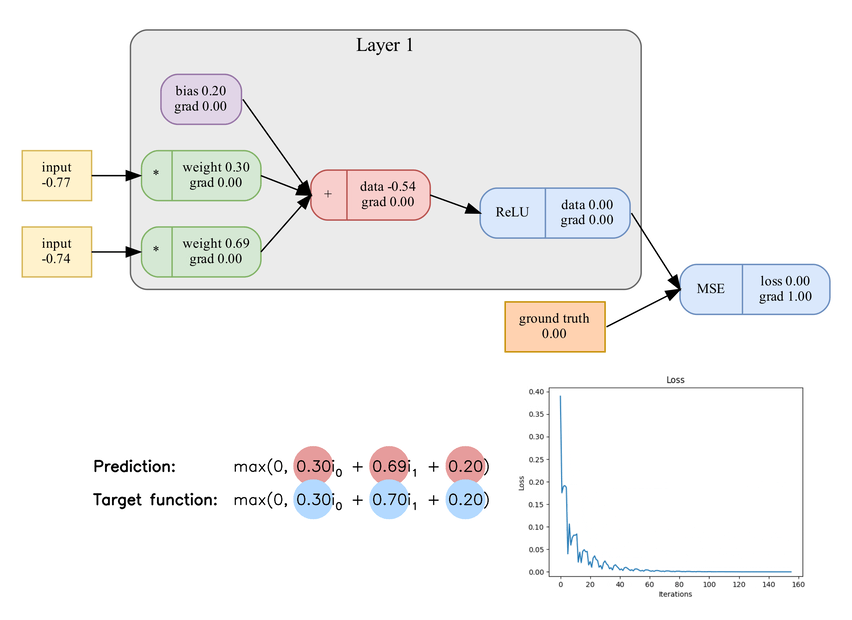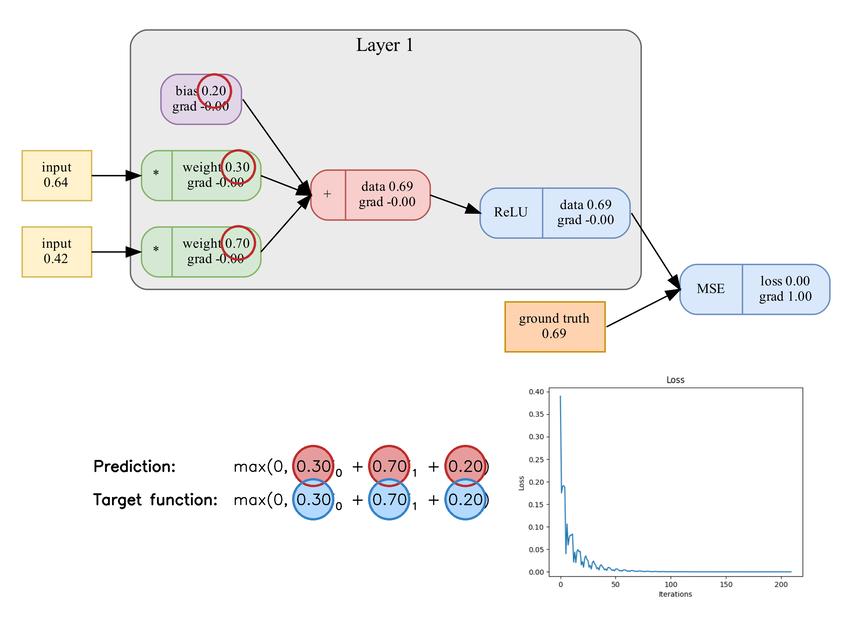
Learning process of a single neuron. Included components: 2 weights, bias, ReLU, mean squared error, and gradient descent.
Introduction
A machine learning model includes model trainable parameters ‒ weights and biases ‒ activation functions, and skip connections. The feed forward process of applying a machine learning model to inputs is called Forward propagation. The forward propagation in a single neuron is expressed as
\[o = a(w \cdot i + b)\]
where \(o\) is an output, \(a\) is an activation function, \(w\) is a weight, \(i\) is an input, and \(b\) is a bias.
Training a machine learning model requires a learning phase to update the weights and biases. This learning phase is called Backpropagation.
Implementation
In this project, I got into First principles of deep learning. I coded an own implementation of a neural network framework without using any deep learning frameworks. The features which I implemented in Python were:
- General
- Forward propagation
- Backpropagation
- Network visualization
- Layers
- Fully connected
- Activation functions
- ReLU
- Softmax
- Loss functions
- Mean squared error
- Cross entropy loss
- Optimizers
- Gradient descent
The code is scalable. It trains and draws any size of a network.
Theory
The main principle behind backpropagation is Derivative. To define how to update a neural network during an iteration, one needs to compute a gradient for each parameter. The gradient determines how much a parameter affects the loss, e.g. a parameter with a gradient 0 contributes nothing to the loss. The gradient of a parameter \(g_{p}\) is defined by the derivative of the loss \(l\) with respect to the parameter \(p\):
\[g_{p} = \frac{dl}{dp}\]
To compute the gradient of a parameter which has operations between the loss and the parameter, require Chain rule. The chain rule expresses the derivative of the composition of two differentiable functions in terms of the derivatives of the two separate functions. By knowing the derivative of a loss \(l\) with respect to a weight \(w_{1}\) and the derivate of the weight \(w_{1}\) with respect to a weight \(w_{0}\), then the derivative of \(l\) with respect to \(w_{0}\) will be:
\[\frac{dl}{dw_{0}} = \frac{dw_{1}}{dw_{0}} \cdot \frac{dl}{dw_{1}}\]
To find the derivative of a weight multiplication and a bias addition functions, we could use the definition of a differentiable function and calculate Limit \(L\):
\[L = \lim\limits_{h \to 0} \frac{f(a + h) - f(a)}{h}\]
In a weight multiplication, the input \(i\) is multiplied by a weight \(w\), hence the function will be \(f(w) = iw\). Now, we can use the definition of a differentiable function and calculate the derivative \(f'(w)\):
$$ \begin{align} f'(w) &= \lim\limits_{h \to 0} \frac{i(w+h) - iw}{h}\\ &= \lim\limits_{h \to 0} \frac{iw + ih - iw}{h}\\ &= \lim\limits_{h \to 0} \frac{ih}{h}\\ &= i \end{align} $$
As seen, the "local derivative" of an input multiplied by a weight with respect to the weight is the value of the input. To obtain the final derivative which we need ‒ the derivative of the loss with respect to the weight ‒ the "local derivative" has to be multiplied with the rest of the chain rule derivatives.
Similarly, let's derive the local derivative of a bias addition. In a neuron, a bias \(b\) is added to the outputs of weight multiplications \(o\). Thus, the derivate of a function \(f(b) = o + b\) will be:
$$ \begin{align} f'(b) &= \lim\limits_{h \to 0} \frac{o + (b+h) - (o+b)}{h}\\ &= \lim\limits_{h \to 0} \frac{o + b + h - o - b}{h}\\ &= \lim\limits_{h \to 0} \frac{h}{h}\\ &= 1 \end{align} $$
Here, the local derivative is 1. Therefore, the derivative of the loss with respect to a bias is 1 multiplied by the rest of the chain rule derivatives.
The derivatives of complex activation functions one could just search online and implement into the code. That's what I did.
Finally, when the gradients are computed for each parameter, it's time to apply them and update the parameters. The simplest optimizer used to apply the gradients is Gradient descent. The derivative shows the direction of growth but when training a neural network, we want to minimize the loss hence take a step (Learning rate) to the direction of a negative gradient. That means, using gradient descent the updated value of a parameter \(p\) will be: \[p_{u} = - g_{p} \cdot r \cdot p_{o}\] where \(p_{u}\) is the updated value of a parameter, \(g_{p}\) is the gradient of the parameter, \(r\) is the learning rate, and \(p_{o}\) is the old value of the parameter.
The last piece of an iteration is to zero gradients. As the gradients have already been applied to the parameters, we do not want to keep them anymore accumulating in the training process.
There you have it, a comprehensive description of how neural networks are built and how they learn. This text explained all the necessary steps required to train a neural network successfully. To enhance the results, there are multiple different components offered which all rely on the theory of derivate.
Interesting findings
While debugging and visualizing the reason why my network didn't learn I came across Dying ReLU problem. Some units may always output zero (they are "dead" neurons) and don't update their weights during training. To address this problem, variations of ReLU have been proposed, such as Leaky ReLU, Parametric ReLU (PReLU), and Exponential Linear Unit (ELU), which aim to allow a small gradient for negative inputs to prevent neurons from becoming completely inactive.
2023 | Github
Tone mapping

Publication of efficient tone curve parameters estimation on embedded pixel processing pipelines.
Machine learning-based HDR sensor image tone mapping designed to run efficiently on ISPs. The work includes 8-bit SDR to 26-bit HDR dataset simulation, image data compression into image histograms, and a fully automated tone curve function parameters prediction. The approach is generic and could be applied on solutions with a predefined analytic function.
The work in numbers:
- 26-bit HDR sensor
- 150 dB dynamic range
- 1k neural network parameters
- 9 kFLOPS curve estimation
- 53 μs runtime on Raspberry Pi 4
- 99.98 % fewer FLOPS than in DI-TM
- 5.85 dB higher PSNR than in DI-TM on real HDR camera images
2024 | arXiv
2024 | Google patents
PDF sensitive data redaction MCP
Redact sensitive data from PDF files before sending them to an LLM.
Problem
Tools like Claude or GPT are incredibly powerful, but they require raw input. If you're dealing with contracts, medical records, or internal documents, that's risky.
Solution
Masquerade acts as a privacy firewall for your files. Just paste in the file path to a PDF, and Masquerade will:
- Automatically detect sensitive data (names, emails, dates, entities)
- Redact the sensitive data
- Let you preview before sending to an LLM
Architecture of the MCP. Powered by Tinfoil API (YC X25) for secure processing.
2025 | Github
AI companion
Talk with a voice clone of your loved one. The AI is personalised to have knowledge of your background.
Elderly people are often lonely and in a risk of getting memory diseases such as Alzheimer's and dementia. Giving them an option to talk with AI can reduce the cognitive decline. Having voice clone of their loved ones was a requested feature especially when they didn't feel safe at home.
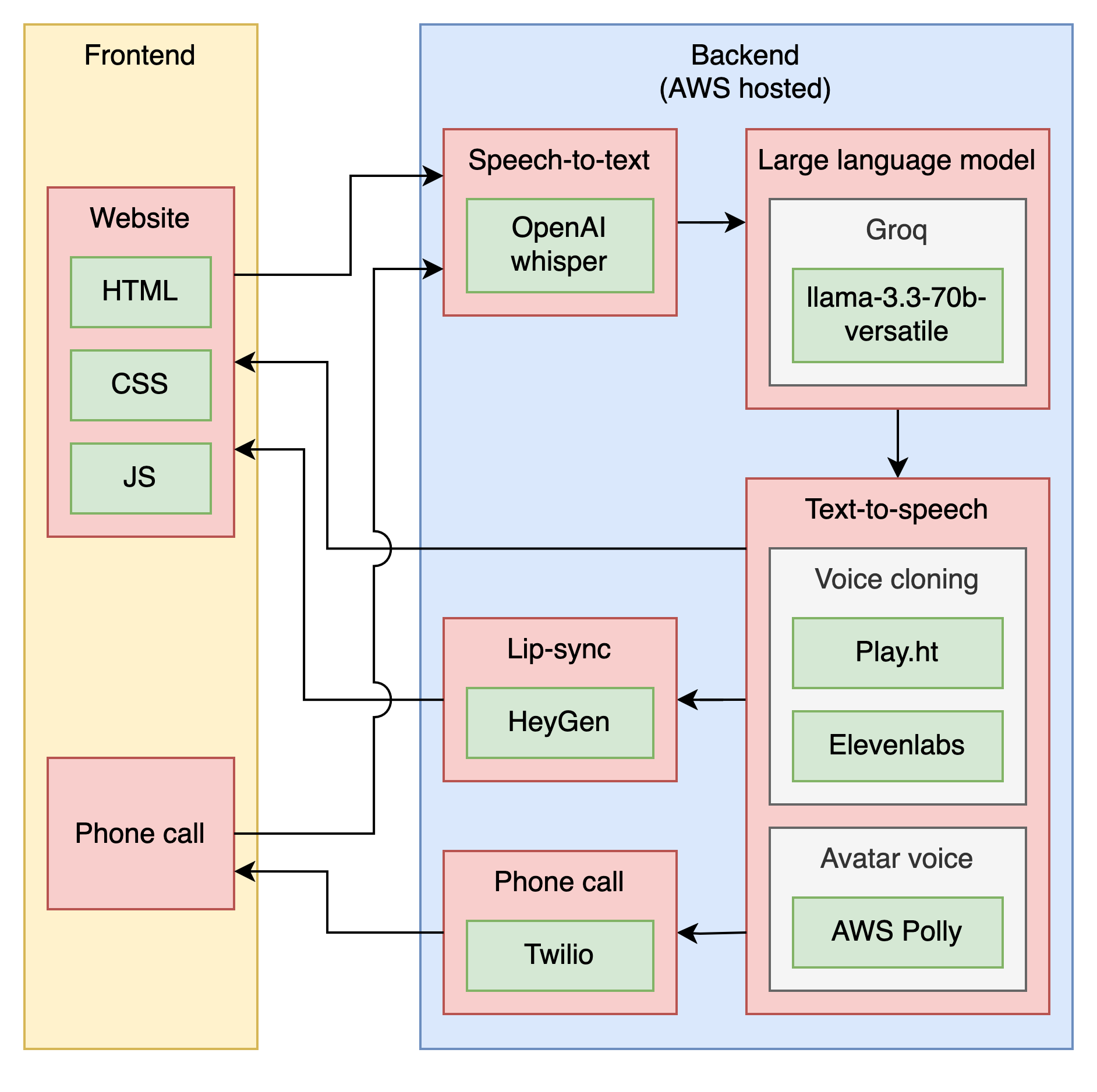
Architecture of the voice clone. Phone calling and web app were created for easy access.
2025 | Github
Deepfake detection
Real-time deepfake face detection and classification. See the moving ghost between the faces causing fake classification.*
Deepfake techniques, which present realistic AI-generated videos of people doing and saying fictional things, have the potential to have a significant impact on how people determine the legitimacy of information presented online. These content generation and modification technologies may affect the quality of public discourse and the safeguarding of human rights ‒ especially given that deepfakes may be used maliciously as a source of misinformation, manipulation, harassment, and persuasion.
I created a deep learning model to identify videos with facial or voice manipulations. The pipeline from input to output was as follows:
- Decode .mp4 video into frames
- Detect faces from multiple frames
- Cluster different humans in a video
- Remove outliers that are not real humans
- Classify the video by using multiple faces from different video frames
The challenge lied in how multi-step the classification had to be. Before being able to classify the video, a face detection algorithm needed to be created. There was a time limit so the face detection had to be fast but also accurate and not every model was able to meet these requirements. Also, in some of the videos there were multiple people present. Obviously, you cannot mess the different faces because that would easily lead to a fake prediction. So clustering was needed. Then sometimes the face detection picked face looking areas such as a pillow with eyes and a mouth or a face picture on a wall. These also had to be filtered out to avoid misleading the classification model. Finally, it was time for the classification model research in which, in the end, I concatenated 9 faces to an input image and fed it to the model.
*Video detection from the public dataset: https://arxiv.org/abs/2006.07397
2020 | Github
Prostate cancer grade assessment
Input of 4x4 concatenated blocks of tissue area with respective predicted and ground truth Gleason segmentation.*
With more than 1 million new diagnoses reported every year, prostate cancer (PCa) is the second most common cancer among males worldwide that results in more than 350,000 deaths annually. The key to decreasing mortality is developing more precise diagnostics.
I created a deep learning model for diagnosing PCa from high-resolution images (average of 800 Mpx per image, maximum size >4000 Mpx).
Achieved validation kappa score 0.91 (6 ISUP grades in the Gleason grading system). Segmented cell with normal, healthy, stroma and Gleason scores from 3 to 5. Classified by using as large tissue area as possible.
*Image segmentation from the public dataset: https://www.nature.com/articles/s41591-021-01620-2
2020 | Github 1, Github 2
Package delivery optimization
Finding optimal route with 301 locations and 4 delivery vehicles.
Challenged myself on learning how complex vehicle routing really is. The underlying problem is to minimize the traveling distance by taking into account constraints and changing environment. The simplest form of minimizing the distance without any constraints is called Traveling Salesperson Problem (TSP). Here are some numbers to understand the complexity of TSP:
- With 4 locations there are (4 – 1)! = 6 possible routes
- With 11 locations there are (11 – 1)! = 3,628,800 possible routes
- With 21 locations there are (21 – 1)! = 2,432,902,008,176,640,000 possible routes
Adding constraints to the routing problem further complicates the optimization. Constraints of the problem include, for example, vehicle capacity, vehicle refill points, traffic jams, cancelled deliveries, or product type limitations. I coded a solution taking into account the following constraints:
- Minimize traveling distance
- N number of vehicles
- M number of packages
- Delivery deadlines of the packages
- Driver's working hours
- Driver's maximum single delivery distance
- Driver's mandatory lunch break
2023 | Github
Acoustic occupancy sensor
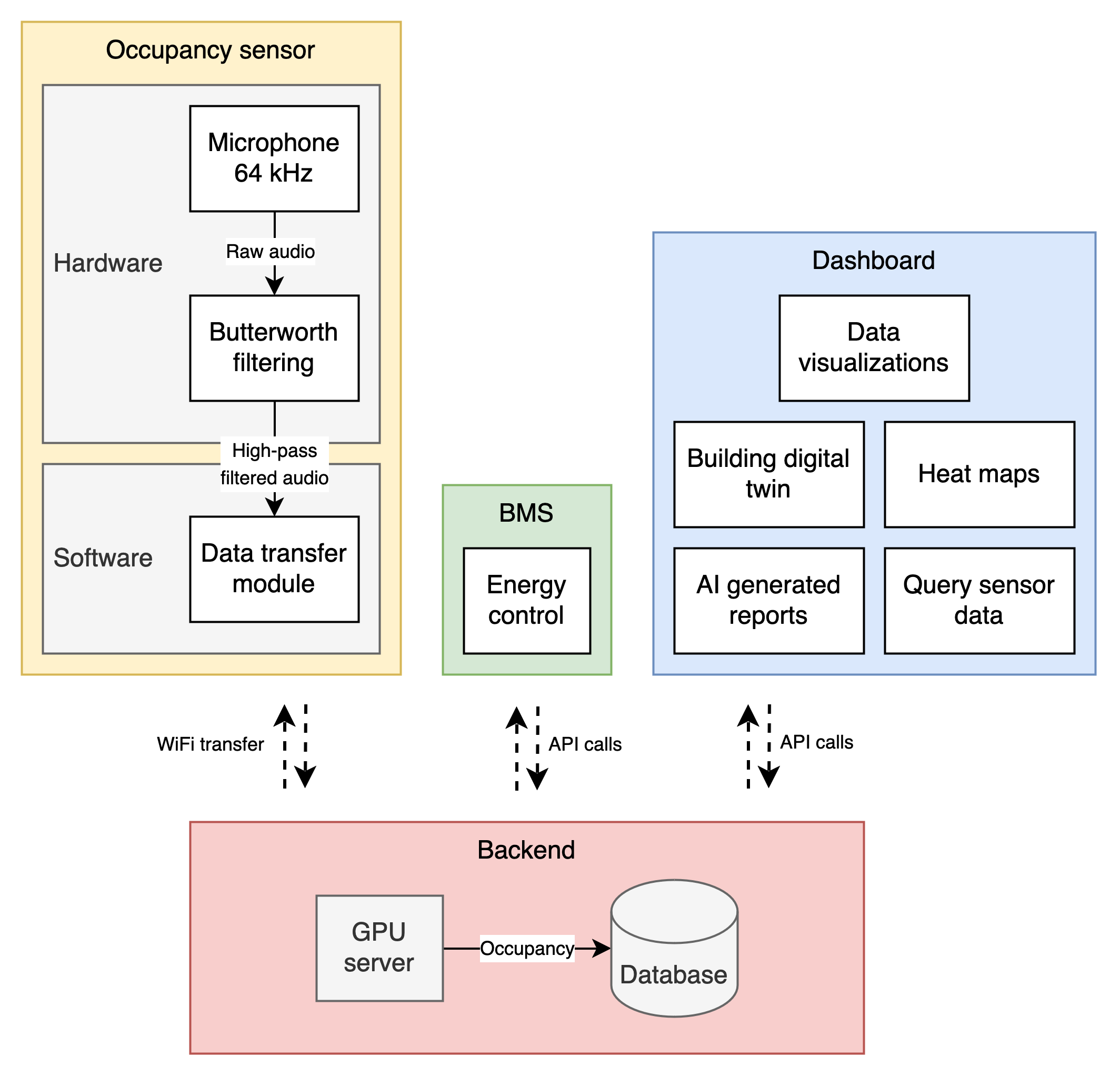
Architecture of our ultrasonic occupancy sensor. The sensor is based on a microphone and filters out speech frequencies to preserve privacy.
Occupancy sensor market has couple problems:
- Cheap sensors (PIR, CO2, Desk counter) are not accurate
- Expensive sensors (Thermal, Depth, Lidar) are accurate but have field-of-view limitation and require installation and wirings
- RGB, Wi-FI, Bluetooth are not privacy preserving not accurate
- Battery life is a problem in many cheaper options
Our solution was to make plug-and-play ultrasonic sensor which is privacy preserving, have no battery life nor field-of-view problems, and is accurate.
Our sensor based on acoustic is privacy preserved because it filters out speech frequencies.
The device is easy to install because it can be plugged into any socket in the room as it has 360 degree field-of-view.
Finally, it is maintenance free because it is constantly powered by the wall socket.
The challenge in this project was to make the algorithm accurate because the people count, for example in a library, can be the same as in a kitchen while the acoustic signals are very different.
2024 | Github 1
2024 | Github 2
2024 | Github 3
2024 | Dashboard
Motion prediction for autonomous vehicles
2D view of roads, traffic agents, and their trajectories.*
Deep learning model for an autonomous vehicle to predict the movement of traffic agents such as cars, cyclists, and pedestrians. The target was to predict future trajectory from a given vector of (x,y) coordinates of the past trajectory.
By converting the coordinates to a bird eye view image, the approach of dealing with vector data was changed to image to image problem resulting in higher accuracy.
*Image simulated from the public dataset: https://arxiv.org/abs/2006.14480
2020 | Github
Molecular translation
Drawn Skeletal formula of an input molecule and a corresponding ground truth InChI text.*
Sometimes the best and easiest tools are still pen and paper. Organic chemists frequently draw out molecular work with the Skeletal formula, a structural notation used for centuries. Recent publications are also annotated with machine-readable chemical descriptions (InChI), but there are decades of scanned documents that can't be automatically searched for specific chemical depictions. To speed up research and development efforts, an automated recognition of optical chemical structures will be helpful.
I created a deep learning model to translate chemical images to InChI text.
*Image sample from the public dataset: https://www.kaggle.com/competitions/bms-molecular-translation/data
2021 | Github
Charuco corner detection

Real-time Charuco corner detection. All of the captured pictures (even without seeing or detecting every corner) can be used for camera calibration because every corner has an ID.
Tool for camera calibration to detect checkerboard corners with corner identifications. It is especially helpful for multi-camera calibration where all the cameras cannot see the whole checkerboard. By knowing the corner identifications, one can use images with partly visible checkerboards for camera calibration.
Used Python OpenCV and embedded it into Matlab as well.
2019 | Github
GPU usage visualization
Real-time GPU usage visualization in a virtual setup. 6 virtual servers connected to the dashboard.
Better visuals of nvidia-smi command.
What nvidia-smi command does is it shows the GPU utilization and memory usage in numbers in a terminal window.
It is not an intuitive view to understand the complete state of a GPU server.
What does this visualization tool then provide:
- Fast understanding of the state of multiple GPU servers
- View of unlimited number of servers on a single page
- Real-time monitoring web dashboard
- User specific statistics
- User sorted GPU programs and their execution times
With the software, it is easier for the machine learning team to distribute workload evenly and stop training experiments which are not needed anymore.
Used technologies: Python, Flask, HTML, CSS, JS, Highcharts, Shell, and threading.
2020
Remote device control
Real-time remote LED control with the mobile phone app, Raspberry Pi and a relay card.
Turning electric devices (up to 2kW) on/off remotely, also known as home automation. Being able to control your electric devices remotely might help you save time of not transporting to your home, cottage or office.
I created a platform where users can login with Google account authentication and access multiple locations which to control remotely.
Overview of the tech:
- Relay card control through the GPIO pins of Raspberry Pi
- MongoDB for user registration and session management
- Routing between client, proxy server, backend server, and a terminal device
- The terminal device controls a relay card that turns the devices either on or off
- Used Node.js, Flask, HTML, JS, CSS, Python, and MongoDB
2018
Smart mirror
Embedded text of the weather, time, and news in a mirror.
Mornings are hectic ‒ you're rushing to get ready but still want to check the weather, local news, and the time without juggling multiple devices. A Smart Mirror solves this by displaying all that information right on your mirror while you get prepared for the day.
Overview of the HW:
- Raspberry Pi
- Monitor
- Reflective window film
Overview of the SW:
- Weather from pirate-weather API
- News from Kauppalehti

Front view of the smart mirror.

Back view of the smart mirror.
2019